Nesta série de artigos, discutirei por que a invenção dos transformers, publicada pela equipe de IA do Google no artigo intitulado Attention Is All You Need (2017), foi tão importante para o aprendizado de máquina e os campos de aprendizado profundo.
Antes de tudo, para entender as realizações dessas ideias propostas, é preciso primeiro entender como as coisas eram feitas antes. Todos nós sabemos que o contexto importa, em alguns casos, importa muito. Por exemplo, ao ler este artigo, você mantém todo o texto anterior em mente para compreender as próximas frases, caso contrário, não faria sentido para você.
Claro, não demora muito para se chegar à conclusão de que pode haver muitas preocupações ao lidar com o contexto. Continuando com a leitura como exemplo, quanto tempo dura o seu contexto? Em outras palavras, de quantas frases (ou ideias) pra trás você se lembra quando lê um texto? Obviamente a resposta é que isso varia. Então, como podemos inserir isso em um modelo?
Usar uma rede neural com palavras em suas respectivas posições como entrada não funcionaria, pois o modelo teria que ter um tamanho de entrada fixo e estabelecemos que um contexto não pode ter um comprimento fixo. Uma das primeiras ideias foi usar RNNs ou Redes Neurais Recorrentes (Recurrent Neural Networks).
Redes Neurais Recorrentes (Recurrent Neural Networks)
As redes neurais recorrentes são assim:

O h na imagem é simplesmente uma função de ativação e pesos. x são as entradas em cada estado e o é a saída de previsão para esse estado. O importante a notar aqui é que os pesos são iguais entre todas as unidades da rede. Isso confere as seguintes vantagens ao modelo:
- Informações sobre estados passados são usadas pela rede para calcular a saída (previsão) do modelo;
- A quantidade de estados passados pode variar indefinidamente;
- O modelo é muito eficiente computacionalmente e, portanto, são facilmente treinados.
Infelizmente, embora as vantagens desse tipo de modelo pareçam grandes, existem alguns problemas que dificultam essa abordagem:
- As informações de vários estados anteriores são quase totalmente perdidas e ficam praticamente indisponíveis na última etapa do cálculo (a última camada);
- Este modelo sofre do problema de gradiente Desaparecendo/Explodindo (Vanishing/Exploding).
Essas limitações restringem os casos de uso desse método a situações em que o número de estados passados a serem considerados é relativamente pequeno. No entanto, a arquitetura proposta pode ser alterada para corrigir esses problemas.
Problema de gradiente Desaparecendo/Explodindo (Vanishing/Exploding)
O problema do gradiente de desaparecendo/explodindo ocorre porque as entradas dos estados anteriores são multiplicadas pelos pesos e passam pela função de ativação muitas vezes antes de atingir a camada final.
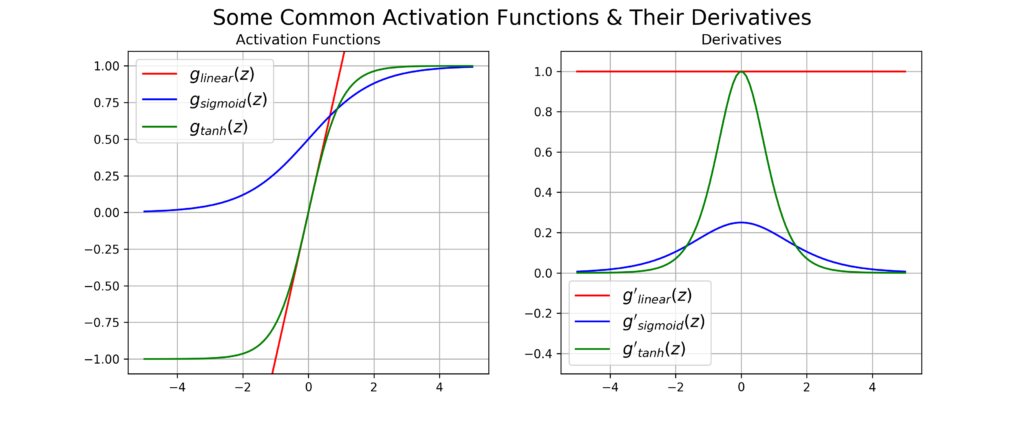
Se dermos uma olhada nas funções de ativação e suas derivadas na imagem acima veremos que nos limites positivo e negativo as derivadas vão a zero, exceto a função linear (que ninguém usa, pois não introduz não linearidade ao modelo). Dessa forma, você pode imaginar que uma entrada sendo multiplicada muitas vezes por um único valor e passada muitas vezes por uma função de ativação teria uma pequena derivada final.
Como a atualização dos pesos depende da derivada parcial da entrada, se for muito pequena, as atualizações ficam muito pequenas também e isso prejudica o desempenho do modelo. O gradiente explosivo tem mais a ver com a forma como os pesos são inicializados, eles podem crescer muito e as atualizações podem se tornar tão grandes que o modelo nunca converge.
Algumas soluções podem ser aplicadas para resolver o problema apresentado:
- Use outras funções de ativação, como ReLU. Esta função de ativação tem uma derivada constante, portanto, o gradiente não desaparece (para uma entrada positiva);
- Gradient clipping: limite o gradiente para um valor máximo;
- Use Batch Normalization: esta técnica aprende um processo de normalização para transformar a saída de cada camada.
Você também pode tentar alterar a arquitetura do modelo para superar esse problema.
Para o próximo artigo, discutirei a próxima arquitetura de Modelos de Linguagem Natural, que surgiu como uma alternativa para resolver os problemas impostos pelas RNNs.