Depois de ver os problemas dos RNNs simples vistos antes, pesquisadores propuseram uma nova abordagem para modelos relacionados à memória. A nova abordagem foi chamada de modelos LSTM.
Arquitetura Long Short Term Memory (LSTM)
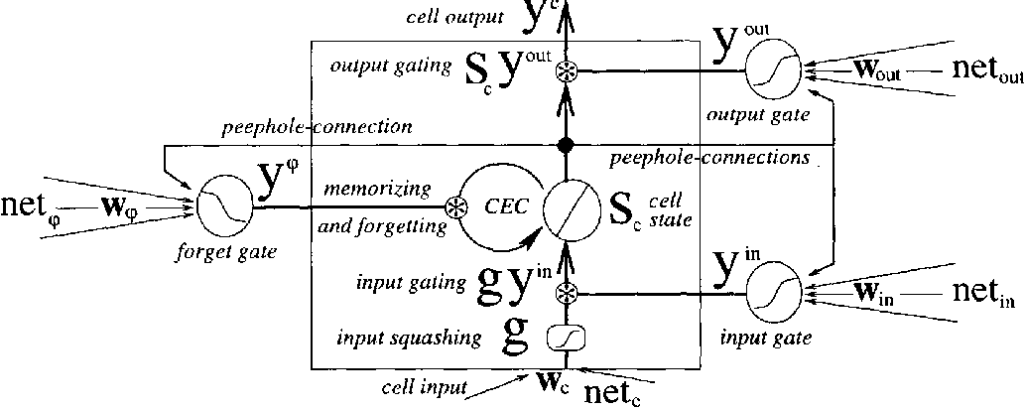
Embora os modelos LSTM sejam uma variante das Redes Neurais Recorrentes, eles apresentam mudanças muito importantes. A ideia é separar o estado da célula dos valores de entrada atuais.

A linha horizontal superior é chamada de estado da célula, é considerada a “memória” de longo prazo da célula. Outro componente especial da arquitetura são os portões. Sempre que você vir um sinal de multiplicação, significa que é um portão.

Portões (gates)
Nesse caso, eles são precedidos por uma função de ativação sigmóide e a explicação para isso é que a saída da função sigmóide vai de 0 a 1, portanto, a operação de multiplicação funciona como um portão para deixar alguma informação passar para o próximo estágio ou ser esquecida . Dessa forma, o estado da célula pode ser alterado e apenas as coisas importantes no momento são lembradas pelo modelo.
A saída
A saída do modelo é o valor h, que pode ser visto como uma versão filtrada do estado da célula. Ele é filtrado no último portão à direita, que tem como entrada o estado da célula passado por uma função tanh.
Outras variantes
conexões de olho mágico
Introduzida por Gers & Schmidhuber (2000), a abordagem olho mágico fornece aos portões o próprio estado da célula como uma entrada.
Gated Recurrent unit (GRU)
Introduzido por Cho, et al. (2014), ele mescla os portões de entrada e de esquecimento em um único portão, chamado de “portão de atualização”. Isso atinge uma arquitetura mais simples, sendo mais fácil de treinar e computacionalmente mais barata. Esta variante ganhou muita popularidade ao longo dos anos.

Conclusão
A introdução da arquitetura LSTM trouxe muito mais possibilidades para resolver problemas. O modelo proposto e suas variantes têm sido utilizados com sucesso em várias soluções relacionadas à memória.
O próximo grande passo que será discutido no próximo artigo é a arquitetura Attention introduzida pelo Google. Uma abordagem que, novamente, mudou tudo no mundo do aprendizado de máquina e criou muito mais possibilidades.